That’s exactly what I’m trying to say. TVAI is built using more open accessible building tools. Meant for multiple platforms, but not blessed with all of Apples latest and greatest. If my my work is any indication, such building tools may never be graced with such endowments.
How worth it would it be for Topaz to start fresh on the Apple-designated development ecosystem. Anything made on that won’t translate or carry over to the other operating systems they are trying to cover.
Again, the solution is already there. They had done optimization with a big speed gain in the past and taken that back due to errors. Now the errors are gone (so in fact it seems Apple have fixed some issues here in the meantime). All they’d need to do is revert to those old fast model files that are already there. So how much work is that?
And to make this a little more concrete:
This is TVAI 4.0.4 when installed from DMG, only benchmark.json edited to use Iris V1 instead of V2:
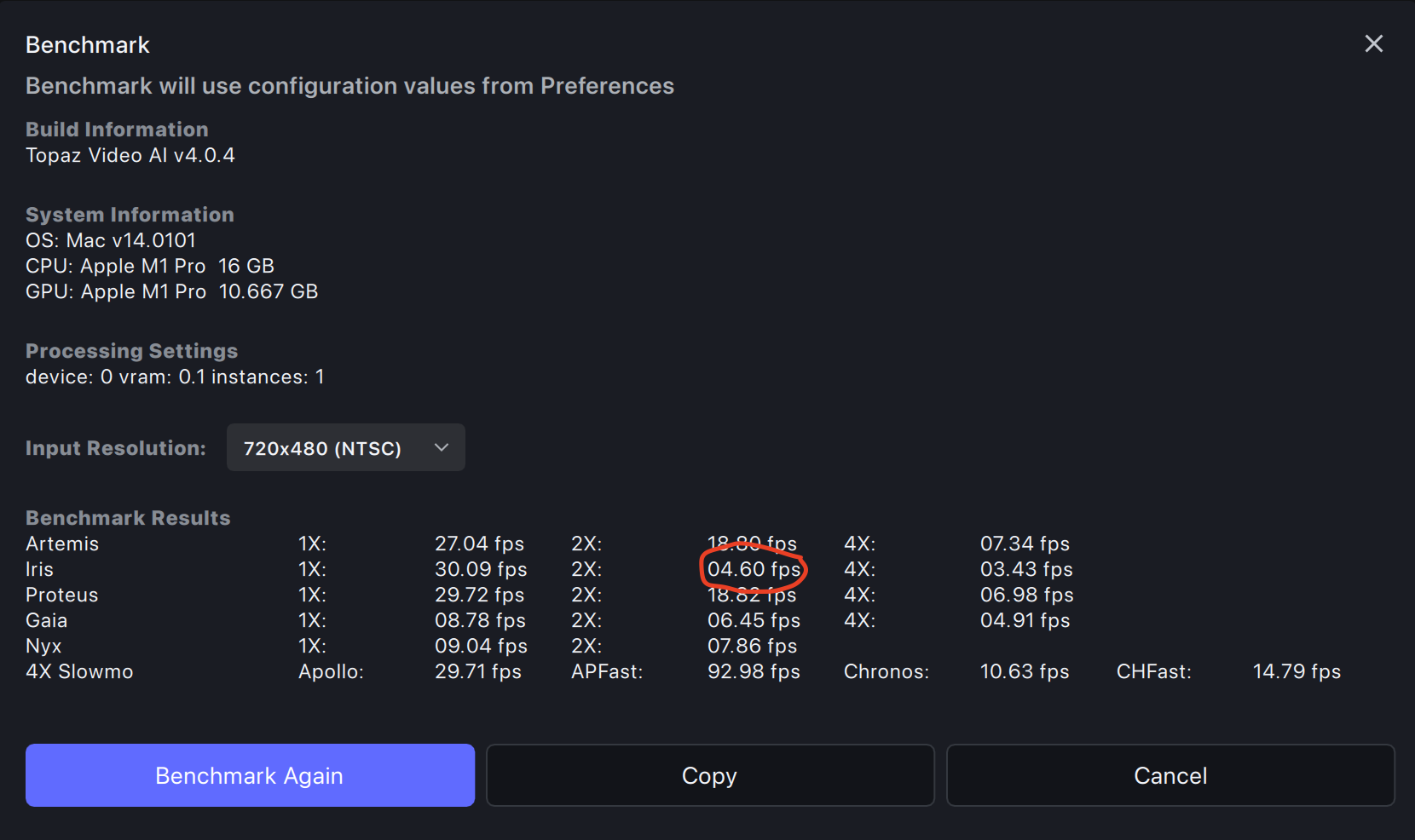
And then the exact same system after I “patched” it with the old Iris V1 model files from Aug. 2023:

And I’d say that this is a dramatic difference with the patched version being nearly 2.7 times faster on the exact same system in my most used scenario (Iris 2x upscale).
1 Like
I’m not talking about Iris. I’m talking about the scaling you mentioned:
But that scaling issue in TVAI can also be seen with the NVidia GPUs if you compare a e.g. 4060Ti to a 4090.
And also is not there on the Mac for most other software, so…
But then this is getting quite OT now.
Apple, in order to improve performances, did the choice to leave Intel to develop their processor based on ARM architecture, that is completely different from Intel architecture. Thus, it is obvious that to get optimized software, developers need to go to new development tools. However, even if Windows is still based on Intel architecture, Microsoft develops also a windows based on ARM, and they will probably in maybe several year switch completely. That means that it could be a good idea to invest in new development tools for these new architectures…
It’s not only the ARM versus X86 differences. The M series chips by Apple have sections for AI computation, graphics and such. It appears that those only get used correctly, if it’s done through whatever development path Apple has created.
It makes sense that new technology might not be compatible with the old ways of doing things. That’s what Nvidia did too. So it’s not unseen nor unheard of.
The gap I don’t understand is why, for the development tools we use at work—and therefore probably to other programs like TVAI—it has been years and we’re not seeing an adoption that gives access to the full benefits of Apple chips. It’s more like they created a limited compatibility layer and called it good enough.
A little disclaimer here. It should read “improve battery performance”. ARM is in no way computationally ‘more preferment’ than X86. It just uses less power wherever it can, whenever it can.
1 Like
Topaz Video AI v4.0.4
System Information
OS: Windows v11.22
CPU: 13th Gen Intel(R) Core(TM) i5-13500 63.67 GB
GPU: NVIDIA GeForce RTX 3060 7.8613 GB
GPU: Intel(R) UHD Graphics 770 0.125 GB
Processing Settings
device: 0 vram: 1 instances: 1
Input Resolution: 1920x1080
Benchmark Results
Artemis 1X: 08.20 fps 2X: 06.04 fps 4X: 01.93 fps
Iris 1X: 08.16 fps 2X: 04.80 fps 4X: 01.55 fps
Proteus 1X: 07.95 fps 2X: 05.25 fps 4X: 01.88 fps
Gaia 1X: 02.62 fps 2X: 01.86 fps 4X: 01.29 fps
Nyx 1X: 03.26 fps 2X: 02.73 fps
4X Slowmo Apollo: 12.40 fps APFast: 35.34 fps Chronos: 06.49 fps CHFast: 10.86 fps
Just curios as to why the 4090 performs around 4 times better than my 3060 at 2X but only around 2 times better at 4X. Could this be due to a memory limitation?
Topaz Video AI v4.0.4
System Information
OS: Mac v14.0101
CPU: Apple M1 Max 32 GB
GPU: Apple M1 Max 21.333 GB
Processing Settings
device: 0 vram: 1 instances: 1
Input Resolution: 1920x1080
Benchmark Results
Artemis 1X: 09.14 fps 2X: 05.53 fps 4X: 01.94 fps
Iris 1X: 09.39 fps 2X: 01.72 fps 4X: 01.24 fps
Proteus 1X: 08.91 fps 2X: 05.10 fps 4X: 01.85 fps
Gaia 1X: 02.90 fps 2X: 01.90 fps 4X: 01.47 fps
Nyx 1X: 03.75 fps 2X: 03.04 fps
4X Slowmo Apollo: 10.54 fps APFast: 33.18 fps Chronos: 03.08 fps CHFast: 05.24 fps
Iris 2x… Ouch!
It’s related to L2 cache size.
Topaz Video AI v4.0.4
System Information
OS: Windows v10.22
CPU: AMD Ryzen Threadripper 3970X 32-Core Processor 127.87 GB
GPU: NVIDIA GeForce RTX 3090 23.77 GB
Processing Settings
device: 0 vram: 1 instances: 1
Input Resolution: 1920x1080
Benchmark Results
Artemis 1X: 25.94 fps 2X: 12.72 fps 4X: 03.49 fps
Iris 1X: 23.49 fps 2X: 13.78 fps 4X: 03.93 fps
Proteus 1X: 25.25 fps 2X: 11.55 fps 4X: 03.46 fps
Gaia 1X: 08.58 fps 2X: 05.65 fps 4X: 03.25 fps
Nyx 1X: 10.14 fps 2X: 08.37 fps
4X Slowmo Apollo: 34.82 fps APFast: 56.30 fps Chronos: 19.28 fps CHFast: 27.03 fps
Topaz Video AI v4.0.4
System Information
OS: Mac v14.0101
CPU: Apple M3 Max 36 GB
GPU: Apple M3 Max 27 GB
Processing Settings
device: 0 vram: 1 instances: 1
Input Resolution: 1920x1080
Benchmark Results
Artemis 1X: 11.42 fps 2X: 07.01 fps 4X: 02.40 fps
Iris 1X: 10.33 fps 2X: 01.92 fps 4X: 01.66 fps
Proteus 1X: 11.10 fps 2X: 06.31 fps 4X: 02.19 fps
Gaia 1X: 03.47 fps 2X: 02.47 fps 4X: 01.65 fps
Nyx 1X: 03.58 fps 2X: 03.26 fps
4X Slowmo Apollo: 12.29 fps APFast: 50.21 fps Chronos: 03.93 fps CHFast: 06.56 fps
Note to Nvidia:
We need at least 10 GB L2 with Broadwell.
1 Like
Or even 1GB!
1 Like
Topaz Video AI v4.0.4
System Information
OS: Windows v11.22
CPU: AMD Ryzen 9 7950X 16-Core Processor 63.727 GB
GPU: NVIDIA Quadro RTX 5000 14.795 GB
Processing Settings
device: 0 vram: 1 instances: 0
Input Resolution: 720x480
Benchmark Results
Artemis 1X: 65.52 fps 2X: 46.01 fps 4X: 15.29 fps
Iris 1X: 61.92 fps 2X: 34.94 fps 4X: 12.25 fps
Proteus 1X: 64.34 fps 2X: 44.93 fps 4X: 14.76 fps
Gaia 1X: 20.73 fps 2X: 14.87 fps 4X: 10.11 fps
Nyx 1X: 15.51 fps 2X: 15.52 fps
4X Slowmo Apollo: 34.49 fps APFast: 201.96 fps Chronos: 48.32 fps CHFast: 64.79 fps
Topaz Video AI v4.0.4
System Information
OS: Windows v11.22
CPU: AMD Ryzen 9 7950X 16-Core Processor 63.727 GB
GPU: NVIDIA Quadro RTX 5000 14.795 GB
Processing Settings
device: 0 vram: 1 instances: 0
Input Resolution: 1920x1080
Benchmark Results
Artemis 1X: 12.14 fps 2X: 08.24 fps 4X: 02.69 fps
Iris 1X: 11.76 fps 2X: 06.26 fps 4X: 02.03 fps
Proteus 1X: 11.82 fps 2X: 08.13 fps 4X: 02.67 fps
Gaia 1X: 03.77 fps 2X: 02.51 fps 4X: 01.66 fps
Nyx 1X: 04.46 fps 2X: 03.98 fps
4X Slowmo Apollo: 05.73 fps APFast: 52.07 fps Chronos: 09.06 fps CHFast: 14.55 fps
Topaz Video AI v4.0.4
System Information
OS: Windows v11.22
CPU: AMD Ryzen 9 7950X 16-Core Processor 63.727 GB
GPU: NVIDIA Quadro RTX 5000 14.795 GB
Processing Settings
device: 0 vram: 1 instances: 0
Input Resolution: 3840x2160
Benchmark Results
Artemis 1X: 02.60 fps 2X: 01.75 fps 4X: 00.55 fps
Iris 1X: 02.44 fps 2X: 01.33 fps 4X: 00.43 fps
Proteus 1X: 02.49 fps 2X: 01.71 fps 4X: 00.56 fps
Gaia 1X: 00.79 fps 2X: 00.53 fps 4X: 00.35 fps
Nyx 1X: 00.75 fps 2X: 00.99 fps
4X Slowmo Apollo: 01.50 fps APFast: 16.09 fps Chronos: 01.92 fps CHFast: 03.60 fps
I think the sweet spot for TVAI is located at 4070/ti / 3080/ti (i prefer the Pro models, RTX ADA gpus)
‘Leaks’ indicate L2 only increasing from 72MB to 96MB on next gen…not nearly enough.
1 Like
Full Ada 102 has 96 mb already.
I dont know.
1 Like
Topaz Video AI v4.0.4
System Information
OS: Windows v11.22
CPU: AMD Ryzen 7 3700X 8-Core Processor 31.906 GB
GPU: NVIDIA RTX A2000 5.8633 GB
GPU: NVIDIA RTX A2000 5.8633 GB
Processing Settings
device: 0 vram: 1 instances: 1
Input Resolution: 1920x1080
Benchmark Results
Artemis 1X: 06.89 fps 2X: 05.29 fps 4X: 01.82 fps
Iris 1X: 07.11 fps 2X: 04.12 fps 4X: 01.32 fps
Proteus 1X: 06.83 fps 2X: 05.15 fps 4X: 01.78 fps
Gaia 1X: 02.12 fps 2X: 01.46 fps 4X: 01.02 fps
Nyx 1X: 02.61 fps 2X: 02.30 fps
4X Slowmo Apollo: 09.68 fps APFast: 31.57 fps Chronos: 05.25 fps CHFast: ... fps
Mac Studio M1 Ultra 48 Core GPU
GPU Benchmark (ca. ~132 Watt for the System)
Topaz Video AI v4.0.2
System Information
OS: Mac v12.0701
CPU: Apple M1 Ultra 64 GB
GPU: Apple M1 Ultra 48 GB
Processing Settings
device: 0 vram: 0.85 instances: 1
Input Resolution: 1920x1080
Benchmark Results
Artemis 1X: 13.73 fps 2X: 08.05 fps 4X: 02.52 fps
Iris 1X: 09.11 fps 2X: 03.48 fps 4X: 01.98 fps
Proteus 1X: 12.95 fps 2X: 06.05 fps 4X: 01.86 fps
Gaia 1X: 04.57 fps 2X: 02.39 fps 4X: 01.86 fps
Nyx 1X: 03.04 fps 2X: 02.45 fps
4X Slowmo Apollo: 11.16 fps APFast: 42.09 fps Chronos: 03.84 fps CHFast: 06.00 fps
Low Power Mode “Neural Engine + CPU” (around 43 Watt with short peaks to 130 Watt)
Topaz Video AI v4.0.2
System Information
OS: Mac v12.0701
CPU: Apple M1 Ultra 64 GB
GPU: Apple M1 Ultra 48 GB
Processing Settings
device: 0 vram: 0.85 instances: 0
Input Resolution: 1920x1080
Benchmark Results
Artemis 1X: 03.75 fps 2X: 02.17 fps 4X: 02.50 fps
Iris 1X: 03.37 fps 2X: 01.33 fps 4X: 00.50 fps
Proteus 1X: 03.86 fps 2X: 02.17 fps 4X: 02.38 fps
Gaia 1X: 02.23 fps 2X: 01.57 fps 4X: 01.03 fps
Nyx 1X: 01.20 fps 2X: 01.48 fps
4X Slowmo Apollo: 06.45 fps APFast: 20.80 fps Chronos: 01.27 fps CHFast: 02.21 fps