Nice job. Just finished a 640x480 video that I scaled 225 Percent, 1440x1080. I used Proteus Auto with a little grain. I got 25 Fps and this while running a plex server and playing a plex video in the background. This was with a Ryzen 9 3900x, 64Gb ram and a RTX 3060Ti. That’s speed I can live with.
I just thought I would report that I am continuing to get export errors when using NVENC AV1 with Apollo Frame Interpolation on vertical videos.
[av1_nvenc @ 000002244C5AD440] Failed locking bitstream buffer: invalid param (8):
Error submitting video frame to the encoder
Steps to reproduce:
Open a vertical video in TVAI (I personally used a video with dimensions 1080x1920 and 23.97fps)
Change the frame rate in the GUI (I personally picked 60fps).
In the frame rate interpolation settings select one of the Apollo models (Apollo, Apollo Soft, Apollo Sharp)
Set the video encoder to NVENC AV1
Start processing the video in the GUI you you will get an “unknown error” shortly after the processing starts. If you run this in the command line instead of the GUI then you will get the NVENC error listed above.
I don’t experience issues if I use other codecs (NVENC H264, NEVENC H265, ProRes, etc).
I also don’t experience issues if I use other frame rate interpolation models like Chronos.
I also don’t experience issues with horizontal videos with similar specifications (1920x1080 at 23.97fps)
GPU: RTX 4090 (Driver 528.02 Studio Driver)
CPU: Ryzen 9 5950X
RAM: 64GB
Windows 11
The optimizations in 3.1 are for all platforms and ensure parallel processing. Since majority of the users are on Nvidia and also Nvidia has better framework support the focus is on Nvidia GPUs. We will be looking into AMD specific optimizations. I might just put out a few AMD GPU specific alphas.
Ps. I keep noticing a really slow download of the updates, when done directly from within the program: when notified of the available update and clicking on Download, the speed is really ridiculous (considering I have FTTH fiber and Photo AI downloads in the same way MUCH faster).
I am notifying you of this problem and hope it will be fixed with the next updates.
As described in the other thread, I can’t imagine a previously slower GPU (RTX 5000) overtaking a faster GPU (W6800) even though it wasn’t capable of doing so before, just because of parallel execution.
If it had been faster, it would have been seen before.
And the parallel execution of four previews actually shows that the GPU (W6800) can do more.
I know that Nvidia has a better support and much better documentation, I can also only reflect what I see and how it behaves and that makes no sense.
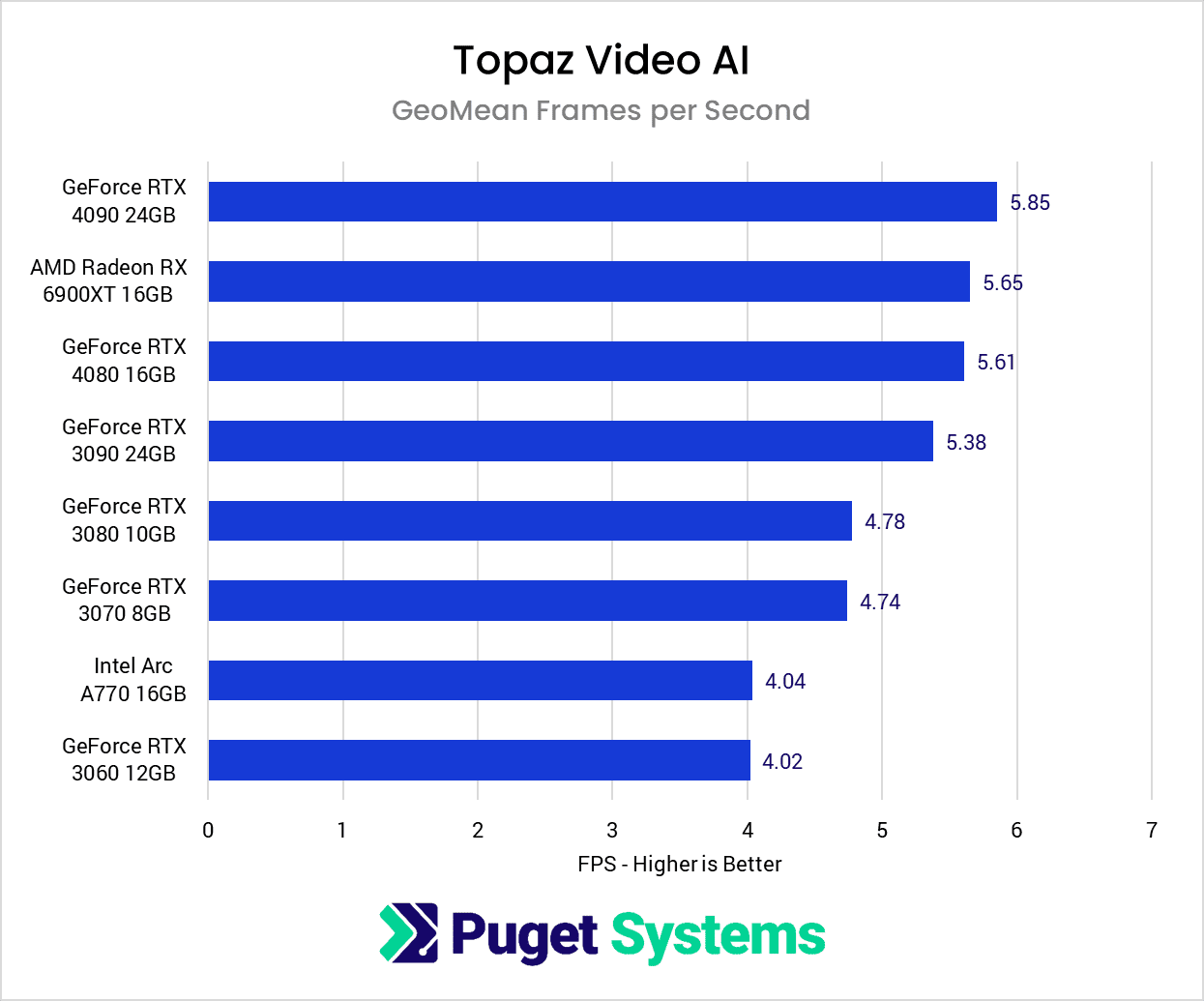
Thats the situation with V3.0.3.0 performed by Puget systems.
RX6900 XT is close to 4090 and in front of 3090.
With parallel execution now the 4090 is two to four times as fast.
And this makes no sense.
People have already written in the forum that it runs poorly on AMD with 3.1.0.
Some GPUs behave better than others as you increase the parallelization of the work. And this has become quite noticeable with recent Nvidia GPUs.
Recent high end consumer Nvidia GPUs typically have much higher raw compute performance than their competitor consumer AMD GPUs. For example, the RTX 3090 with 35.58 TFLOPS of FP32 compute performance compared to the RX 6950XT with 23.65 TFLOPS of FP32 compute performance.
Yet in a large number of applications that make heavy use of FP32, this does not lead to a noticeable performance boost for Nvidia. And this is because a lot of applications have a hard time making their work parallel enough to take full advantage of the highly parallel GPU design Nvidia has started using on their consumer GPUs in recent years.
It’s POSSIBLE that the changes made in TVAI to increase the parallelization of tasks ends up favoring Nvidia more than AMD GPUs due to differences in the two manufacturers GPU designs. Or the way parallelization was implemented favors Nvidia. However, I’m doubtful this is the main cause for the performance you’re observing.
The use of Tensor RT on Nvidia compared to AMD could be having an impact?
There could be driver or compiler bugs for AMD that’s causing a performance decrease (Another application I use had a 30% performance decrease on AMD a few months ago due to a compiler bug)?
Maybe there’s a lack of proper optimization for AMD hardware?
This is all just speculation. And you’re better off waiting and seeing what the “AMD optimizations” that @suraj has suggested may be being worked on, brings for your hardware.
You also have to keep in mind that the increase in parallelization of TVAI also probably increases the memory bandwidth requirements of the applications. Nvidia and AMD once again differ there when comparing “typical competitors”. For example, the RTX 3090 has a memory bandwidth of 936.2 GB/s
while the RX 6950XT has a memory bandwidth of 576.0 GB/s. And they’re laid out differently, for example, the RTX 3090 having a wider memory bus. This could also be having an impact on the performance scaling of different GPUs with the update. But once again, this is all speculation and it’s possible very few of these factors have an impact on the scaling of TVAI across different hardware.
I really just wanted to let you know that as code changes are made to improve performance, the scaling of that performance improvement may be different across different hardware, more so across different vendors due to differences in chip design, drivers, memory layout, memory speed, etc.
I did reinstall 3.0.12 and the performance is 1 frame slower to 3.1.1.1b.
Therefore, I assume that I am correct with my assumption.
I did compare a 2018 Turing GPU vs a RDNA2 2020 GPU.
Quadro RTX 5000 = 22 fps in 3.1.0.
FP16 (half) performance
22.30 TFLOPS (2:1)
FP32 (float) performance
11.15 TFLOPS
Bandwidth
448.0 GB/s
Radeon Pro W6800 = 8 - 11 fps in 3.1.0(1b) → 6 - 8 fps in 3.0.12. → 6.6 fps in 2.6.4
FP16 (half) performance
35.64 TFLOPS (2:1)
FP32 (float) performance
17.82 TFLOPS
Bandwidth
512.0 GB/s
You are of course right with your data, no question, but I have tested both GPUs in the same system.
Except for version 3.0.12, which I tested today on the W6800.