Actually giving some tries with 4/5 RTX 3070 and things does not end up very well …
5x MSI RTX 3070 Gaming X Trio
➔ Unable to run benchmark
➔ Load models perfectly, start to encode
➔ GPU load 5x 68%, then “Error” after few minutes
➔ Rock solid under Linux with such setting
PCIE settings
- Gen2 x4 BIOS set to 4x4x4x4 1 lane ~ 5 GTs / 500 MBs
- Gen2 x4 BIOS set to 4x4 1 lane ~ 5 GTs / 500 MBs
- Gen2 x4 1 lane ~ 5 GTs / 500 MBs
- Gen2 x4 BIOS set to 4x4x4x4 1 lane ~ 5 GTs / 500 MBs
- Gen2 x4 BIOS set to 4x4 1 lane ~ 5 GTs / 500 MBs
4x MSI RTX 3070 Gaming X Trio
- Gen3 x4 BIOS set to 4x4x4x4 1 lane ~ 8 GTs / 985 MBs
- Gen3 x4 BIOS set to 4x4 1 lane ~ 8 GTs / 985 MBs
- Gen3 x4 BIOS set to 4x4x4x4 1 lane ~ 8 GTs / 985 MBs
- Gen3 x4 BIOS set to 4x4 1 lane ~ 8 GTs / 985 MBs
➔ Benchmarkable, results below
Topaz Video AI v5.0.4
System Information
OS: Windows v11.22
CPU: AMD Ryzen Threadripper 2990WX 32-Core Processor 31.899 GB
GPU: NVIDIA GeForce RTX 3070 7.8301 GB
GPU: NVIDIA GeForce RTX 3070 7.8301 GB
GPU: NVIDIA GeForce RTX 3070 7.8301 GB
GPU: NVIDIA GeForce RTX 3070 7.8301 GB
Processing Settings
device: 4 vram: 1 instances: 0
Input Resolution: 1920x1080
Benchmark Results
Artemis 1X: 17.35 fps 2X: 07.72 fps 4X: 02.28 fps
Iris 1X: 26.20 fps 2X: 11.73 fps 4X: 03.10 fps
Proteus 1X: 25.96 fps 2X: 11.72 fps 4X: 03.25 fps
Gaia 1X: 15.41 fps 2X: 09.20 fps 4X: 02.96 fps
Nyx 1X: 06.63 fps 2X: 08.91 fps
Nyx Fast 1X: 22.01 fps
4X Slowmo Apollo: 13.69 fps
APFast: 26.88 fps
Chronos: 18.60 fps
CHFast: 12.51 fps
16X Slowmo Aion: 20.57 fps
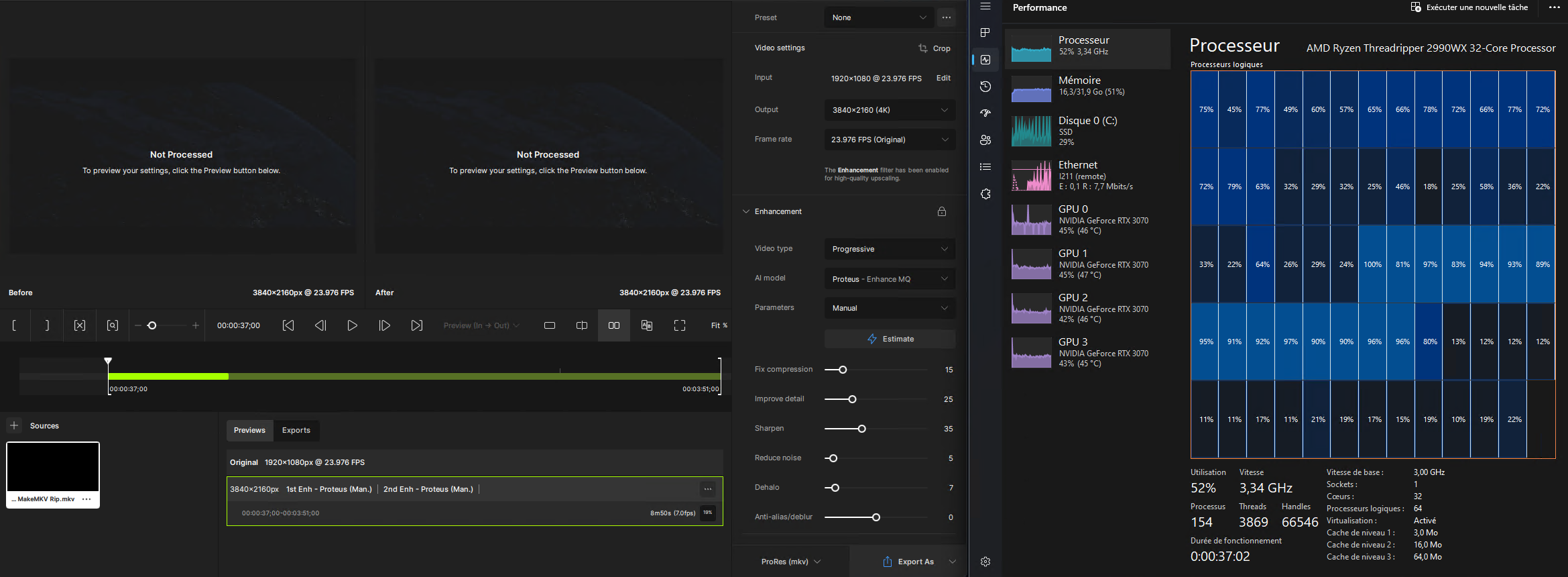
Very poor GPU workload / CPU fully loaded but no use of SMT / LAN bottlneck (X550-T2 coming in) / SSD bottleneck (Evo 970 dedicated workload coming in)
So … Any expert have an opinion about this ?
Any PCIE bottelneck (explaining so poor GPU load) ? ➔ In such case, will buy PCIE x16 riser
Any coding bottneck with multiple GPU ?
➔ If so, any new release supporting it ?
Any models to improve ?
➔ For sure it does need tons of. Idid many tries with many models, some objets are handled very strangely (second plan face(do not make effort to volunteer second plan realisator, they need to stay blurry) : nose and eyes, tube that has a contrast tinted part, grass crossed, ears of wheat, contrasted leafy branches), poor stars or space environment understanding, motion compensation.
On oposite side, awesome job on : naked trees, wheel with radial legs, texts, faces, denoising (really kicking the ass), deinterlacing (even with pure crap interlaced) is perfectly patched
Moving now to 5.1 for some new tests.
Feel free to bring what could be devs/ admin  Ready to help (want my money valuable
Ready to help (want my money valuable  )
)
Regards