This is super cool! @erasmo.topazlabs take a look ![]()
1 Like
Any plan to improve speed of STARLIGHT Mini (and all other AI model) with latest updates for NVIDIA GPU’s Architecture???
6 Likes
They lower the output quality, thats why its faster.
Nvidia did this all the time over the years to boost speed.
fp32->fp16->int8->int4
Gemini did explain to me.
“In order to run diffusion models more efficiently on hardware (especially on devices with limited resources), they are often quantized. This means that the weights and activations of the model are reduced from high precision floating point numbers (e.g. 32-bit) to lower precision ones (e.g. 8-bit or even 4-bit integers).
While quantization can significantly increase execution speed and reduce memory requirements, it inevitably leads to a loss of precision. The challenge is to find a balance between performance and visual quality. Recent research has focused on developing quantization methods that minimize the loss of quality.”
2 Likes
I did another preset, this time for the compression-destroyed 1st episode of “Les Mondes Engloutis”, French animated series from 1985, (I found it on Dailymotion and downloaded it as a test video, it’s 99.3MB, so I can’t upload it here). But I can MEGA it. ![]()
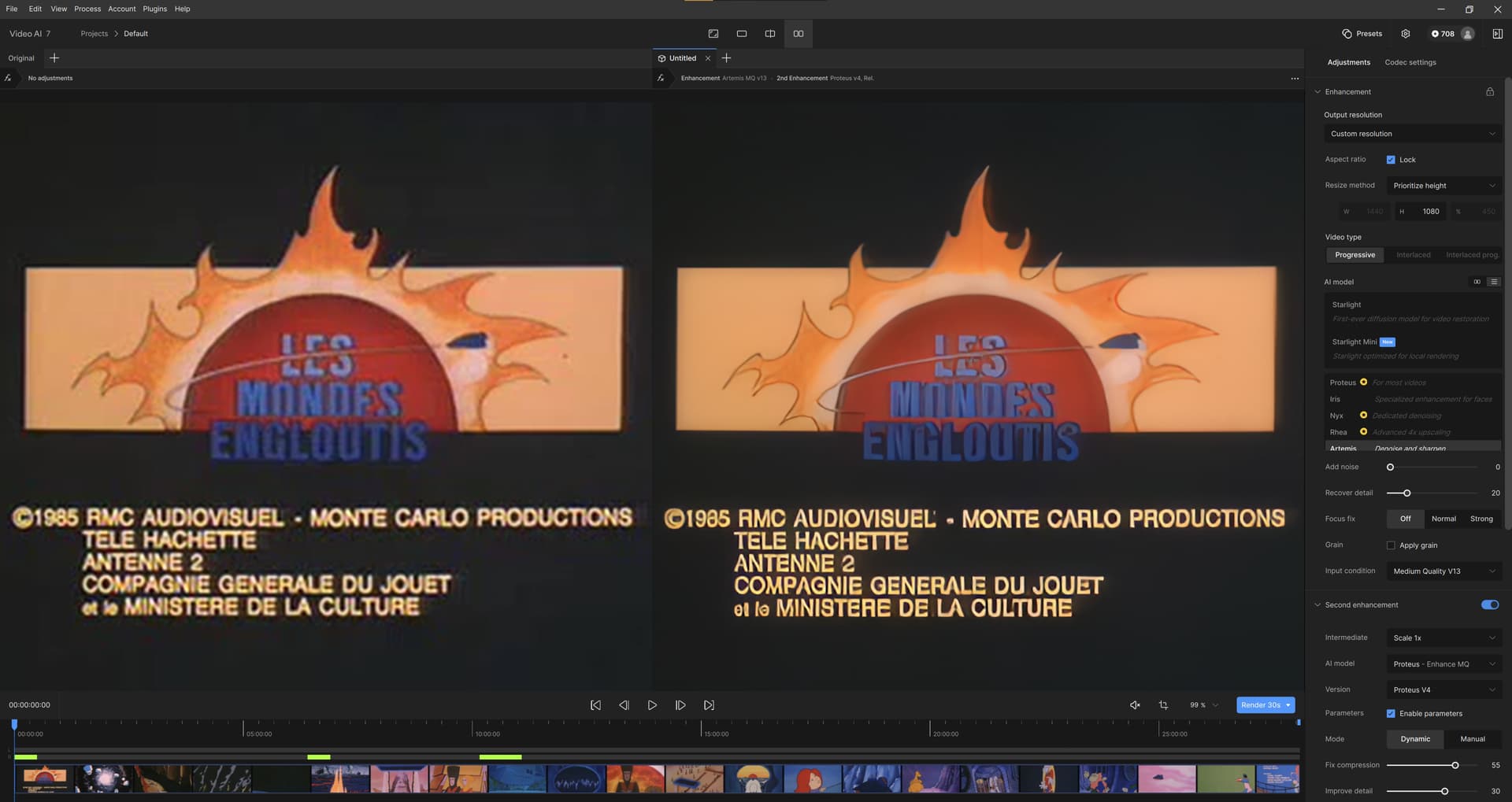
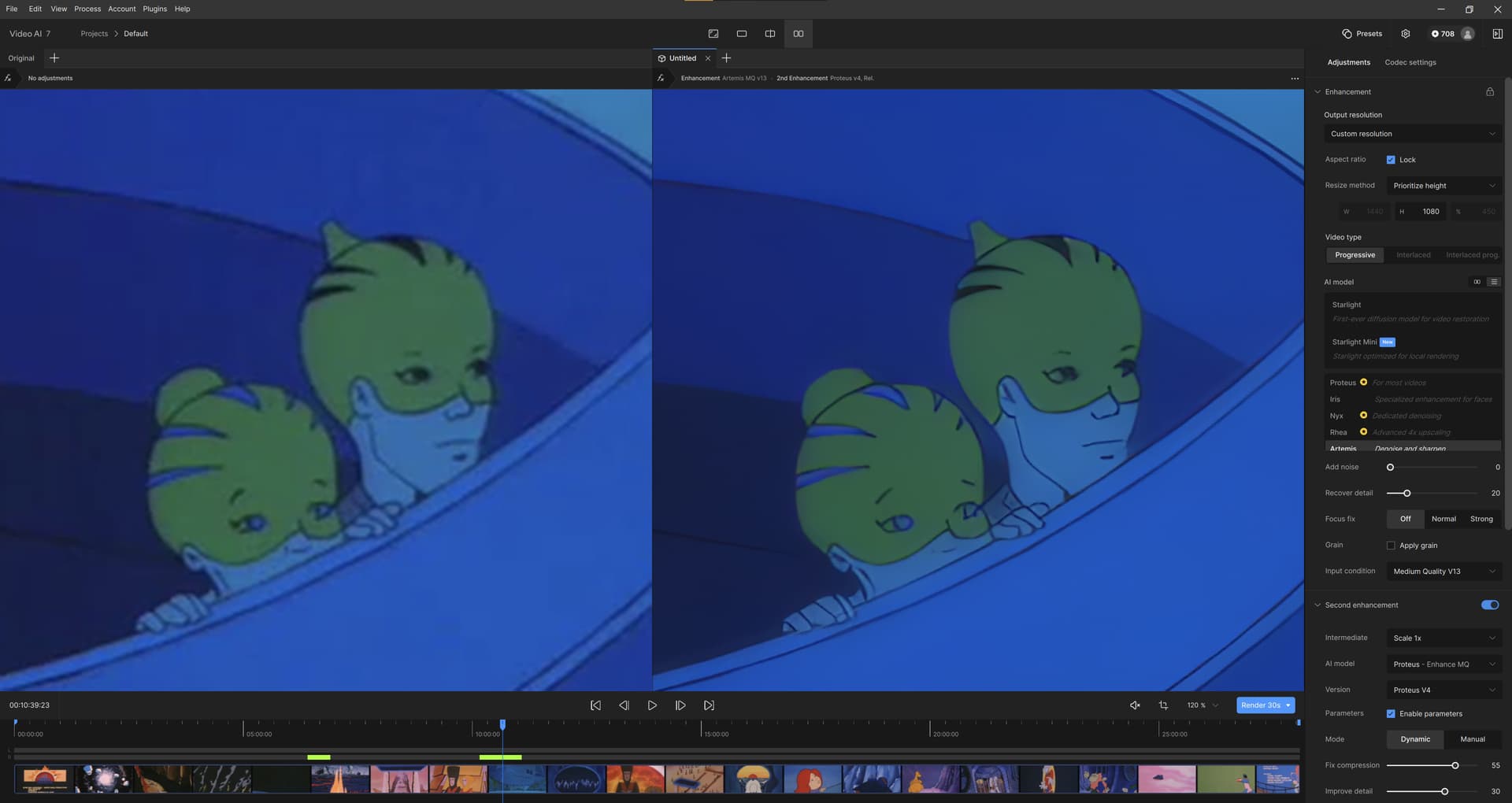
Les Mondes.json (3.1 KB)
EDIT: Is it possible, that this beta has such speedup, upscaling from 320x240 to 2880x2160 with over 30 fps with Gaia v5 model on RTX 3090?
I wonder, if this nasty ‘square-ish’ looks is normal for this model though - I remember Gaia v6 being very cool with VEAI 1.6.1 back in the day:
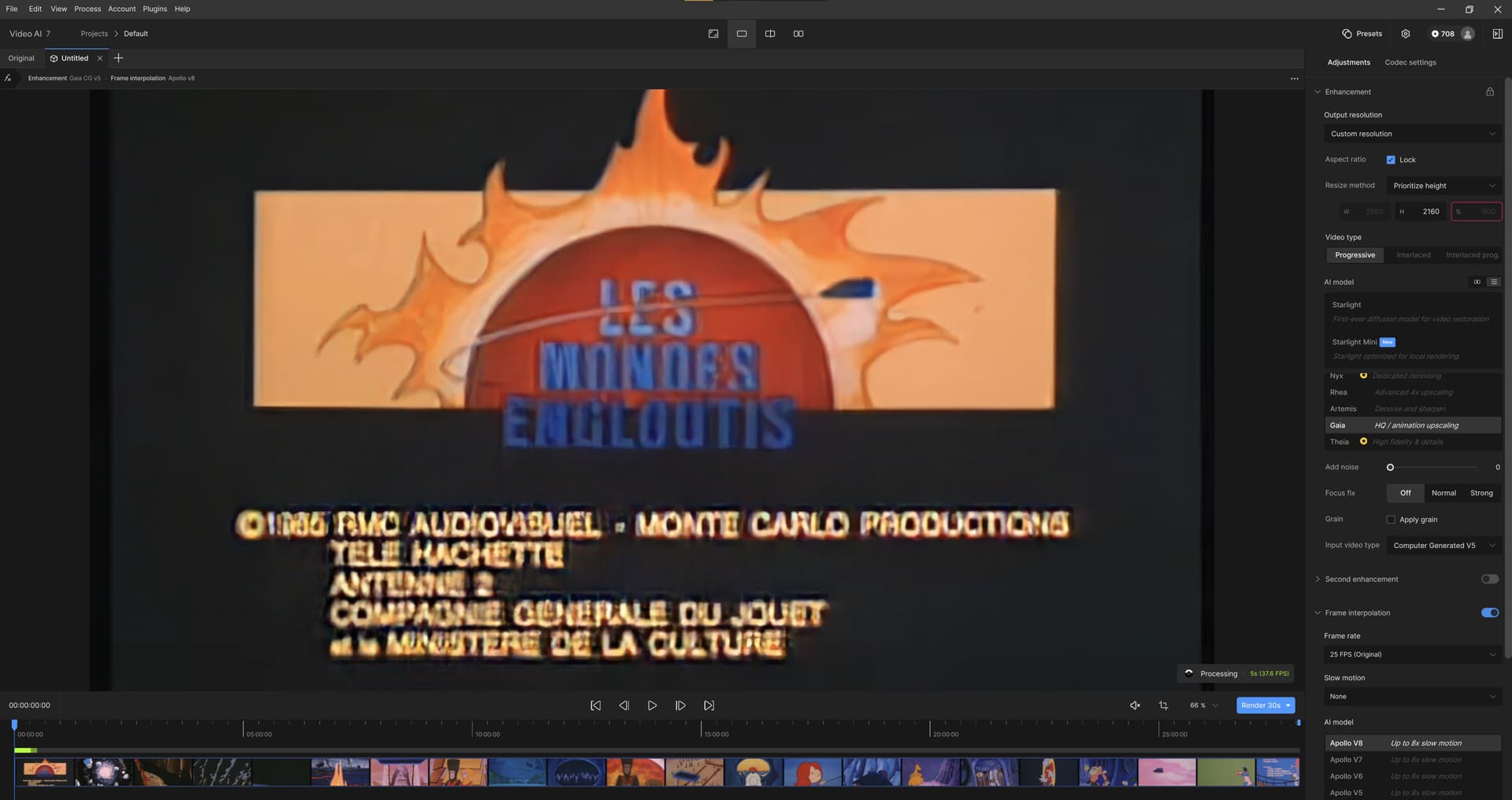
2 Likes
When programmers compare the outputs.
They need to compare it to the best possible output, not the one from the quantisation before.
So if the best possible output is fp64, you need to compare the other quantisation steps to this and not fp8 to fp4, because you already did lost so much that the step from 8 to 4 is not much but from 64 to 4 its a big leap.
That has absolutely nothing to do with the original video.
It’s just a mishmash of compression.
And what Video AI makes of it is a flat image with no content.
Ordy et les grandes découvertes - Générique d’ouverture 1
When I look at the video that has already been made available for download, I can imagine that my theory of 4-fold compression becomes 8-fold.
That means.
Compressed recorded. (DVD, Internet etc.)
Compressed processed. (free software, non-lossless workflow, lossy data formats)
compressed exported. (optimized for internet)
uploaded compressed. (youtube, insta etc.)
So next step.
Compressed recording. (OBS, screens recording, low quality)
compressed processed. (free software, non-lossless workflow, lossy data formats)
compressed exported. (optimized for internet)
uploaded compressed. (youtube, insta etc.)
Simply wow.
I did another session with Gigapixel yesterday and the artifacts, the lack of precision, the look, I can associate all that with compressed training data.
Hair changes/connects, things get edges.
Of course, if a developer just throws enough data at his model then something useful will emerge because the mass of information will eventually produce something useful.
At some point, however, the tipping point will come and the models will produce more and more garbage because the lack of precision and the artifacts in the data play an increasingly important role.
It’s like astrophotography, we take hundreds of scrap images that contain the signal we want, we just need to have enough images.
But if we had better technology, we wouldn’t need so many images, so much computing power, so much memory and so much time and headache.
Just look at the images produced by bloom.

before

after
Looks great, of course, the contours have remained the same but the content of the surfaces has changed.
The person is different, it now has a beard, the connections on the “helmet” have become hair.
Leather has become metal.
I believe that Bloom is Redefine, just with a different name, for social media.
I always compare AI with No face from Spirited away, it offers gold that turns to stone in the end.
Anime Movie :- Spirited Away The “No face” monster is a symbol/metaphor for greed#anime#spiritedaway
1 Like
Well, I’ve never said I’ll get the ‘original’ video with those presets, it’s impossible at this point. Even SL Mini won’t get that (although it gets close to that lowres [768p?] “eighties” image).
I was only trying to get rid of the nasty compression artifacts.
1 Like
I wonder how new MAX model in the newest TPAI beta will fare with these compressed frames? ![]()
I have just intentionally compressed images to edit them with max.
The model failed.
Everything is going completely in the wrong direction.
At first I’m usually surprised at what the models can do, but after not too much time I become disillusioned because the models only have an insular talent.
It is hit and miss, indeed, but this kind of AI processing is developing steadily towards better and better solutions. We have to be patient and enjoy what we have at the moment, I believe. ![]()
By the way, maybe some of those legacy SD video material is meant to be watched on CRT screen after all? Even upscaled to 576p/480p? You know, “hardware antialiasing” of the CRT tube and all that. ![]()
Everywhere there is only talk of increasing speed, rarely does anyone ask whether what is being done makes any sense at all.
Did you know that less than 1% of ChatGPT users pay for it?
A billion dollar grave.
1 Like
Well, the same goes for generative imagery. But for the restoration purposes - I’m all in, provided the original footage or imagery (analog) is also preserved for safety reasons. The same should be applied for the written text by human hand.
we will still have a lot of fun with AI what it does socially, in the end I think humanity will become stupid because everyone will ask the AI and no longer have to think for themselves. Something like in the movie “Idiocrazy” ![]()
2 Likes
Its aready running on amd?
i need a little help guys, its better an 4090 or a 5080 to run topaz in the fast way possible??
1 Like
I think the 4090 is faster… I could be wrong though.
1 Like
Yeah, it’s looking like the benchmarks of the 4090 are technically faster. They do seem pretty close though, and I know for sure that some of the benchmark numbers are not close to what real processing gets.
The 4090 has more memory, i would go for this one.
But the 4090 came out in 2022 and does not have the most recent tech.
2 Likes